정규식 개인정보 마스킹(핸드폰번호, 이메일, 계좌번호, 여권번호, 주민번호)
안녕하세요. owenCho 입니다. 오늘 포스팅은 [개인정보 마스킹] 입니다.
내가 관리하고 프로젝트 중 KT에서 운영하는 여러 사내 프로그램에 대한 문의를 위해 상담사와 고객을 연결해주는 채팅상담이라는 서비스가 있다. 상담사와 사용자간 대화중 사용자가 본인의 개인정보를 알려줘야할 케이스가 발생하는데, 채팅이 끝난 후 대화이력에서 노출되었던 사용자의 개인정보를 마스킹 처리해달라는 이슈를 받았다. 이전에도 정규식을 이용해 string에서 원하는 특정 부분을 추출한 기억이있지만, 정규식을 만들때마다 문법을 다시보곤 해서 이 기회에 정리를 해보려고 한다.
정규식 문법
정규표현식 메타 문자
메타문자를 이용하면 특정한 규칙을 가진 여러 단어를 하나의 패턴으로 함축할 수 있다.
- ^ : 문자열의 시작을 표현한다. [ … ] 내부에서 쓰이는 경우라면 뒤의 패턴에 일치하지 않는 것을 선택한다.
- ^http : 문자열이 http로 시작하는 경우에만 매치하며, 중간에 나타난 http에는 매치하지 않는다.
- ab[^0-9]: “ab” 뒤에 숫자가 아닌 것이 오는 것에만 매치한다. (“abc” – O, “ab1” – X)
- $ : 문자열의 끝을 표현한다.
- them$ : 문자열이 “them”으로 끝난 경우에만 해당 “them”에 매치한다.
- \b : 단어의 경계. 문자열 시작과 끝, 공백, 개행, 탭, 콤마, 구두점, 대시문자 등이 올 수 있다.
- \bplay\b : 는 단어 경계로 구분되는 “play”에는 매치한다. 하지만 “playground”의 “play”에는 매치하지 않는다.
- \B : \b가 아닌것. 정규식 메타문자에서는 흔히 대문자로 표현한 것은 소문자로 표현한 문자의 반대를 의미한다.
- \bplay\B : “play”뒤에 단어의 경계가 아닌 것이 올 때에만 매치한다. “playground”, “playball”의 “play”에 매치한다. 뒤에 오는 “g”, “b” 등의 문자는 포함하지 않는다.
- \s : 공백 문자 및 탭 문자에 매치한다.
- \S : 공백 문자가 아닌 한 글자에 매치한다.
- \d : 숫자에 매치한다. [0-9]와 같다.
- \D : 숫자가 아닌 문자에 매치한다. [^0-9]와 같다.
- \w : 단어를 만들 수 있는 글자. 알파벳 대소문자, 숫자, 언더스코어를 포함한다. [A-Za-z0-9_] 와 같다.
- \W : \w에 포함되지 않는 문자들
- \n : 개행문자. \r은 캐리지 리턴이다.
- \ : 이스케이프용 문자. 정규식 상의 특별한 의미가 있는 문자들을 문자 그대로 쓸 때 앞에 붙인다. \^ 라고 쓰면 “^” 문자 그대로를 가리킨다.
- . : 아무 문자 1개에 대응된다. 공백 역시 문자 1개로 취급된다
수량 한정자
동일한 글자 혹은 동일한 족(family)이 n 개 만큼 나오는 경우에 수량한정자를 뒤에 붙일 수 있다.
- ? : 바로 앞의 글자 혹은 그룹이 1개 혹은 0개 이다.
- apples? : s?는 “s”가 있을 수도 있고, 없을 수도 있다는 의미로, “apple”, “apples” 모두에 매치된다.
- * : 0개 이상이다.
- n\d* : n 뒤에 숫자가 0개 이상이라는 의미. “n”, “n1”, “n123” 에 모두 매치된다.
- + : 1개 이상이다.
- n\d+ : “n” 뒤에 숫자가 1개 이상이다. “n1”, “n123″에 매치되지만 “n” 에는 매치되지 않는다.
- {n} : n 개가 있다.
- n\d{2}$ : “n”뒤에 숫자가 2개 있다. “n12” 에 매치되지만, “n”, “n1”, “n123″에는 매치되지 않는다. n\d{2}라고 했을 때에 “n123″에서는 n12까지만 매치하고 3은 제외한다.
- {n, m} : n개 이상, m개 이하가 있다.
- n\d{2, 3}$ : “n12” , “n123″에는 매치되지만 “n1″이나 “n1234″에는 매치되지 않는다.
- m은 생략가능하며, 생략되면 n개 이상이라는 의미가 된다.
마스킹 처리(핸드폰, 이메일, 주민번호, 여권번호, 계좌번호)
- 사용자가 채팅한 내용을 message 라고 가정했을때, message 내용 중 원하는 부분을 추출하여, 마스킹하는 작업을 해보자.
핸드폰
- 가운데 번호 4자리 중 뒤에 2자리, 끝에 번호 중 앞에 한자리 마스킹
ex) 010-45**-*568, 010-56**-*447, 010-72**-*359
message = message.toString().replace(/[\s-]{0,2}?(010)[\s-]{0,2}?(\d{1,2})(\d{2})[\s-]?(\d{1})(\d{3}))/gi, `$1-$2**-*$5`);
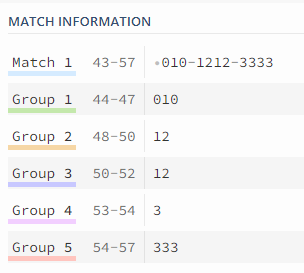
정규식을 뜯어보면 괄호로 그룹화하고 다시 원하는 결과로 그룹들을 조합하여 가공하는 과정이 중요하다. group1부터 group5까지를 $1부터 $5로 표현한다. 마스킹처리를 원하는 $3, $4 그룹을 제외한 나머지 그룹으로 조합하여 $1-$2**-*$5 로 가공하면 원하는 부분이 마스킹되어 출력된다.
[\s-](010)[\s-]{0,2}?(\d{1,2})(\d{2})[\s-]?(\d{1})(\d{3})
[\s-] : 핸드폰번호 앞에 공백이나 - 가 0개이상 2개이하 있을수도 있고 없을수도 있다.
(010) : 첫번째 그룹 010으로 시작 => $1
[\s-]{0,2} : 첫번째 그룹 뒤에 공백이나 - 가 0개이상 2개이하 있을수도 있고 없을수도 있다.
(\d{1,2}) : 두번째 그룹으로 연속된 숫자가 1개이상 2개이하이다. => $2
(\d{2}) : 세번째 그룹으로 연속된 두개의 숫자 => $3
[\s-]? : 핸드폰 가운데 숫자 이후에 공백이 오거나 -가 올수있다.
(\d{1}) : 네번째 그룹으로 휴대폰 뒷번호 맨앞 숫자 하나 => $4
(\d{3}) : 다섯번재 그룹으로 휴대폰 뒷번호 네자리 숫자 중 끝 3자리 => $5
위의 이미지와 같이 실제로 String 에서 해당 정규식으로 추출이 정상적으로 되는지 확인하기 위한 사이트가 존재한다. 필자는 이 사이트에서 여러 정규 표현식을 대입하여 정규식을 학습했다. 정규식을 색깔별로 구분하여 구분하거나 이해하기 쉬웠고, 옆에 설명도 자세하게 나와 있어 매우 유용했다.
이메일
- @앞에 3자리 마스킹 처리
ex) abc***@naver.com, dkfdo***@yahoo.com, df***@daum.net
message = message.toString().replace(new RegExp('.(?=.{0,2}@)','g'),'*');
이메일 특성상 @ 를 기준으로 앞뒤에 알파벳 소문자,대분자, 숫자 등이 존재한다. @ 앞 세글자만 마스킹 처리해주기 위해, .(?=.{0,2}@) 정규식을 사용해 @앞을 전방탐색 ?= 하여 @ 앞 3글자를 마스킹 하였다.
주민번호
- 주민번호 13자리 중 뒤 6자리 마스킹 처리 ex) 951016-1******
message = message.toString().replace(/(\d{6})-([1-4]{1})([0-9]{6})\b/gi,`$1-$2******`);
- (\d{6}) : 연속된 6자리 숫자 (주민번호 앞자리)
- ([1-4]{1}) : 1~4 중 숫자 하나(주민번호 뒷자리 중 맨 앞 숫자)
- ([0-9]{6}) : 마스킹할 주민번호 뒷자리 7자리중 끝 6자리
여권번호
- 여권번호 1뒤 4자리 마스킹 처리
ex) M5689****
message = message.toString().replace(/([a-zA-Z]{1,2})(\d{3,5})(\d{4})/gi,`$1-$2******`);
- ([a-zA-Z]{1,2}) : 여권 앞에오는 1~2글자 알파벳
- (\d{3,5}) : 표기될 연속된 3~5자리 숫자
- (\d{4}) : 마스킹 처리될 연속된 뒤의 4자리 숫자
계좌번호
- 앞 6자리만 표기, 나머지는 마스킹처리
ex) 110-371-******
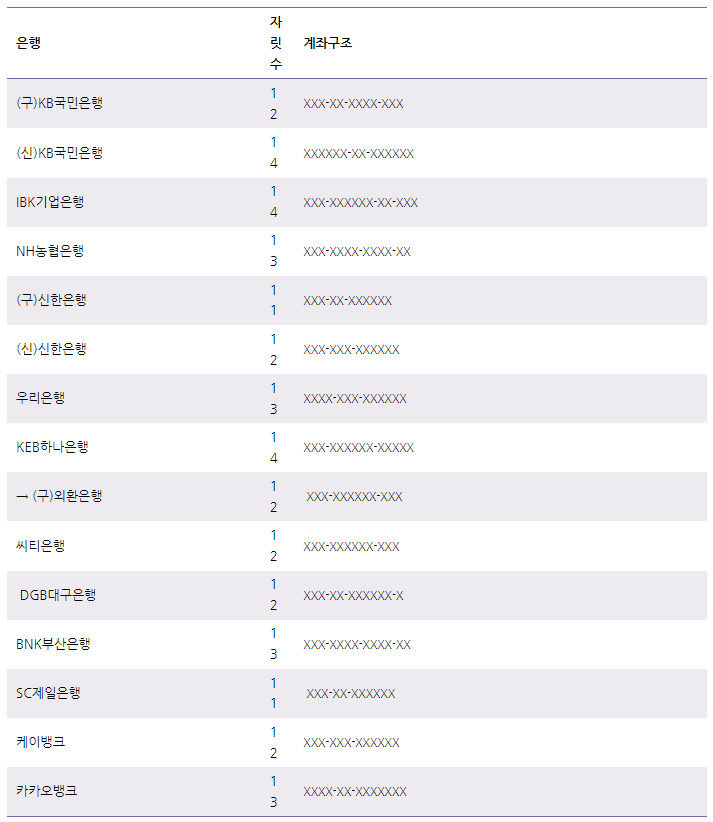
위와 같이 계좌번호는 11~14자리까지 존재한다. 하지만 - 가 들어가는 위치가 달라 유형별로 정규식을 만들어 주었다.
message = message.toString().replace(/(\d{3})-?(\d{2})(\d{1})(\d{3})-?(\d{3})\b/gi,`$1-$2-$3***-***`);
message = message.toString().replace(/(\d{6})-?(\d{2})-?(\d{6})\b/gi,`$1-**-******);
message = message.toString().replace(/(\d{3})-?(\d{3})(\d{3})-?(\d{2})-(\d{3})\b/gi,`$1-$2***-**-***`);
message = message.toString().replace(/(\d{3})-?(\d{3})(\d{1})-?(\d{4})-(\d{2})\b/gi,`$1-$2*-****-**`);
message = message.toString().replace(/(\d{3})-?(\d{3})-?(\d{6})\b/gi,`$1-$2-******`);
message = message.toString().replace(/(\d{4})-?(\d{2})(\d{1})-?(\d{6})\b/gi,`$1-$2*-******`);
message = message.toString().replace(/(\d{3})-?(\d{3})(\d{3})-?(\d{5})\b/gi,`$1-$2***-*****`);
message = message.toString().replace(/(\d{3})-?(\d{3})(\d{3})-?(\d{3})\b/gi,`$1-$2***-***`);
message = message.toString().replace(/(\d{3})-?(\d{2})-?(\d{1})(\d{5})-?(\d{1})\b/gi,`$1-$2-$3*****-*`);
message = message.toString().replace(/(\d{3})-?(\d{3})(\d{1})-?(\d{4})-?(\d{2})\b/gi,`$1-$2*-****`);
message = message.toString().replace(/(\d{3})-?(\d{2})-?(\d{1})(\d{5})\b/gi,`$1-$2-$3*****`);
message = message.toString().replace(/(\d{4})-?(\d{2})-?(\d{7})\b/gi,`$1-$2-*******`);
댓글남기기